进程、线程、协程
为了满足多任务需求,人们发明了三套执行体:进程、线程、协程,以及各种执行体之间的通信机制。
分时系统
操作系统需要执行多任务模式,有两个方法:
- 提升CPU颗数
- 提升CPU核心数
对于物理硬件来说,我们通常希望尽可能设备体积尽可能小,因此现代计算机通常CPU颗数不多,但是核数较多
如果是单个CPU的单核要实现多任务,则需要需要操作系统切分多个时间片进行分时处理
执行体
分时系统在执行任务时需要将当前任务挂起,恢复另一个任务并移交执行权限,这个过程有几个问题需要解决:
- 任务是什么?由什么构成?
- 任务状态有哪些,任务是怎么被保存和恢复的?
- 什么时刻需要进行任务切换?
操作系统层面提供了两种任务机制,进程和线程,任务至少包含两个要素:
- 下一个执行位置
- 自身状态
保存这两个关键信息的介质是:
- 寄存器:上下文切换时,保存当前时刻寄存器的值,将寄存器值置为下一个任务挂起时的状态,继而开始执行下一个任务
- RAM(内存):每个进程都有自己的内存空间,任务切换时需要找到自己的虚拟内存映射表,映射表同样是从寄存器读取
总结:
- 上下文 = 寄存器中的值
- 上下文切换 = 寄存器值保存、恢复过程
进程
进程的出现源于计算机同时运行多个软件的需求。
1、系统提供的一种任务隔离单元,不同进程之间资源相互隔离
2、fork模式是一种进程间通信的特殊方式:子进程复制副进程,之后父子进程各干各的事
3、进程的同步、互斥、通信
- 竞态条件:不同执行体需要同时访问操作同一资源时,执行结果依赖于操作时序
- 互斥、临界区:将一段代码定义为临界区,阻止不同执行体同时进入临界区,这种行为叫做互斥
- 信号量:执行体进入临界区之前获取一个令牌,成功则进入,否则等待其他执行体释放令牌
- 互斥量(锁):mutex互斥体,lock -> do something -> unlock
线程
在同一个软件内同样存在多任务需求。
- 共享进程资源空间,彼此之间相互信任
- 早期Linux系统不存在线程,因此进程需要承担一部分线程的功能,因此可能才有了fork模式
协程
对于海量并发场景,直接使用系统多线程会存在这些成本问题:
1、时间成本
- 执行体切换(寄存器保存和恢复),腾挪余地有限
- 执行体调度的开销,成本随线程数量线性升高
- 执行体之间的同步和互斥成本
2、空间成本
- 执行体状态保存
- 执行体堆栈
- 线程局部存储(TLS)
为了解决这些问题,以golang为代表的编程语言在用户态实现了协程机制:
- 堆栈初始大小仅4k,可以按需扩容,最高可达百万并发级别
- 提供了channel的同步和互斥机制
- 实现了同步IO+线程池的包装(GMP),将大量并发包装到了有限数量的线程中
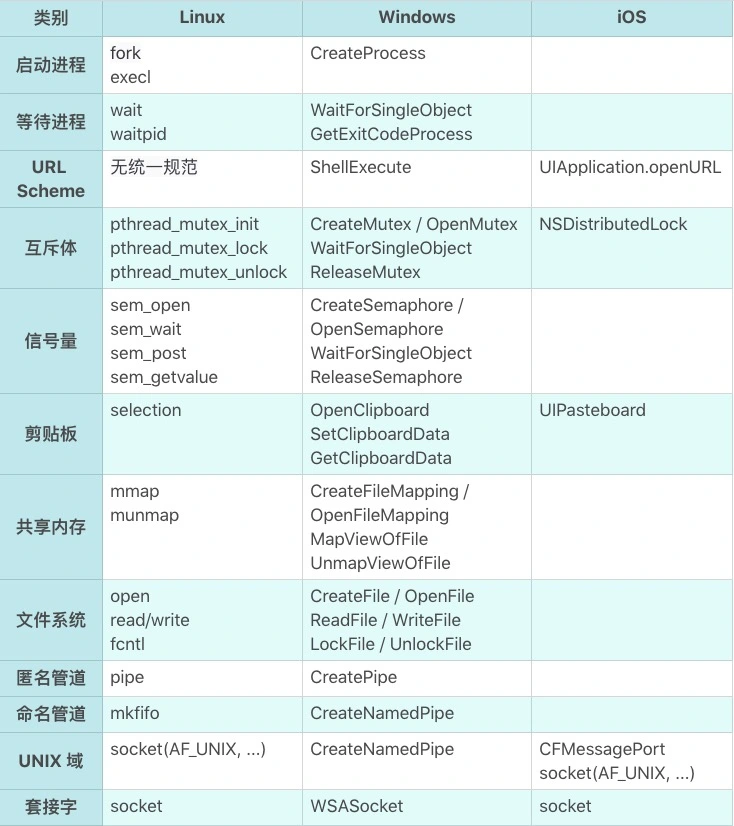
通信机制
这里整理一下广义的进程通信机制。